
Why document variability — not borrower qualification — is the real constraint on Non-QM scale.
When the File Breaks Before Underwriting Starts
Your DSCR pipeline is growing. Your underwriting criteria are clear. But files are stalling before they ever reach a credit decision — and the reason isn’t borrower quality. It’s the documents that can’t be processed at the speed your volume demands.
A rent roll submitted as a screenshot. A lease agreement photocopied at an angle. An operating statement built in a spreadsheet and exported as an untagged PDF. Each one requires a processor to stop, interpret, manually extract, and re-enter data. Each one costs time your pipeline cannot afford to lose.
A misclassified document isn’t an inconvenience — it’s a suspended file, a missed SLA, and a borrower who calls your competitor.
The Specific Breakdown: Document Stacking in Non-QM Files
DSCR loans don’t carry the standardized income stack of a conventional file. In its place, operations teams receive an unpredictable combination of lease agreements, rent rolls, bank statements, operating statements, entity documentation, and prior-year tax records — sourced from individual borrowers, property managers, CPAs, and LLCs.
For a multi-property investor, that stack multiplies by property count. A borrower with eight rental units may submit eight separate leases in eight different formats, alongside bank statements across three accounts and operating statements prepared by two different bookkeepers.
It is estimated that each manual review adds 12 to 20 minutes of processing time per document. Assuming an average of 10 documents per DSCR file, and 100 DSCR loans per month, this translates to 200+ hours of processing time — before a single underwriting decision is made.
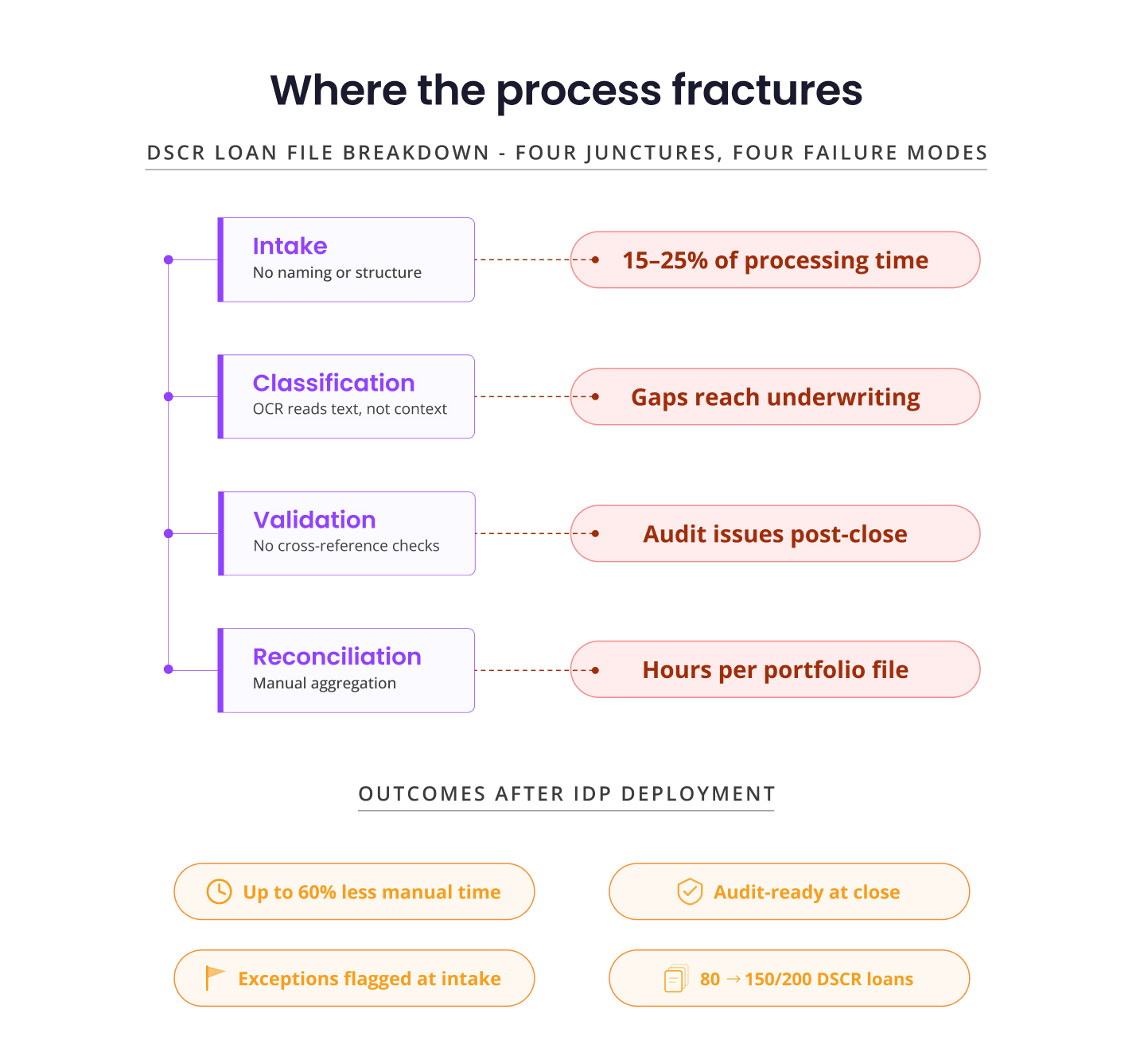
Where the Process Fractures
Failure occurs at four specific junctures:
- At intake, documents arrive with no consistent naming, format, or structure. Processors must identify, sort, and index each file manually — a task that could consume 15 to 25 percent of total loan processing time.
- At classification, traditional OCR systems extract text but might lack contextual understanding, making it difficult to reliably distinguish a lease amendment from an original lease or identify that a bank statement covers only 10 of the required 12 months. It flags nothing. The gap reaches underwriting undetected.
- At validation, data extracted from one document is rarely cross-referenced against another. Rent amounts in the lease go unverified against bank deposit patterns. DSCR ratios are calculated on income figures that haven’t been reconciled against actual cash flow. The number looks right. The audit finding will not.
- At reconciliation, multi-property files require consolidation across dozens of documents. Manually assembling a portfolio-level income picture from individual property files takes hours — and any error in that aggregation directly affects the credit decision.
Legacy OCR doesn’t know what it doesn’t know. It returns a field value. It doesn’t tell you the field was wrong, incomplete, or inconsistent with three other documents in the same file.
How DocVu.AI Closes the Gap
DocVu.AI’s Intelligent Document Processing platform is designed around the structural reality of Non-QM files — not the assumption that documents will arrive clean and standardized
Format-agnostic ingestion means the system processes native PDFs, scanned documents, photographed pages, and spreadsheet exports without format-specific templates. A rent roll from AppFolio and a handwritten lease from a self-managing landlord go through the same pipeline with consistent output.
Context-aware extraction goes beyond field identification. The system understands document type, section hierarchy, and relational context — extracting rent amounts from lease agreements while simultaneously recognizing that the same figure should appear in the bank statement deposit history. The system can apply validation rules during extraction workflows.
Field-level validation applies rule sets specific to DSCR underwriting requirements: minimum lease term coverage, DSCR ratio thresholds, and income continuity across statement periods. Exceptions are flagged before the file reaches the underwriter, with specific references to the source document and field.
Cross-document intelligence enables portfolio-level reconciliation. For multi-property borrowers, a properly configured DocVu.AI can aggregate property-level income data across all submitted documents and deliver a consolidated income view — with discrepancies identified and attributed to their source.
DocVu.AI integrates with loan origination systems via APIs, supports human-in-the-loop validation for low-confidence fields, and maintains audit trails for compliance — ensuring that automation operates within existing underwriting workflows and compliance frameworks.
The Operational Result
Lenders using DocVu.AI for DSCR document processing have reported reductions of up to 60 percent in manual processing time per file. Underwriting cycle times compress because exceptions are resolved at intake, not discovered mid-review. Audit trails are complete and field-attributed at close, reducing post-close defect rates and secondary market exposure.
Critically, throughput scales without proportional headcount growth. As an example, a team that earlier processed 80 DSCR loans per month at full capacity can now sustain 150 to 200 with the same staffing level, because the primary document-processing constraint is significantly reduced.
Operational capacity in DSCR lending is no longer determined by how fast your team can read documents. It is determined by how intelligently your system can process them.
Next Step
Explore how DocVu.AI’s IDP platform eliminates document-level bottlenecks in your DSCR and Non-QM workflows. Visit docvu.ai to see the system in the context of your operational stack.





