
Where operational throughput breaks down in document-heavy workflows — and the specific system capabilities that fix it.
The Throughput Problem No One Fixes at the Root
Most mortgage operations leaders know exactly where their pipeline slows down. Files land in the queue with documents out of order, critical fields missing, and data that hasn’t been verified against anything. Processors work through them sequentially, manually, one document at a time.
The problem isn’t effort. It’s structure. Many document-heavy workflows were originally designed for lower volume and higher tolerance for delay. Neither of those conditions applies anymore.
Every avoidable manual step in a loan file is a compounding liability — not just a process inefficiency.
Where the Bottleneck Actually Lives
A standard conventional loan file contains 50 to 100 pages of documents spanning income verification, asset statements, appraisals, title work, and compliance disclosures. A Non-QM or DSCR file can run significantly deeper — with rent rolls, operating statements, lease agreements, and entity documents layered on top.
Each document type arrives in a different format, from a different source, with different field arrangements. Processors must identify the document, determine what it contains, extract the relevant data, verify it against other documents in the file, and flag anything that doesn’t reconcile. That sequence runs on every document, in every file, every day.
At 300 loans per month, if manual document handling consumes even 2 to 3 hours per file across intake, indexing, verification, and exception management, that alone can consume 600 to 900 hours of processing time before underwriting analysis begins, depending on workflow maturity, loan complexity, and document volume. That is where cycle time is lost. That is where costs accumulate. That is the operational constraint most lenders are trying to manage by adding headcount rather than removing the cause.
Adding processors to a manual workflow doesn’t solve a throughput problem. It scales the cost of it.
Five Ways AI Reduces Mortgage Processing Bottlenecks
The following five capabilities address the specific failure points in document-heavy mortgage workflows. Each one reduces manual intervention at a distinct stage of processing — and each one has a direct effect on time, cost, or risk.
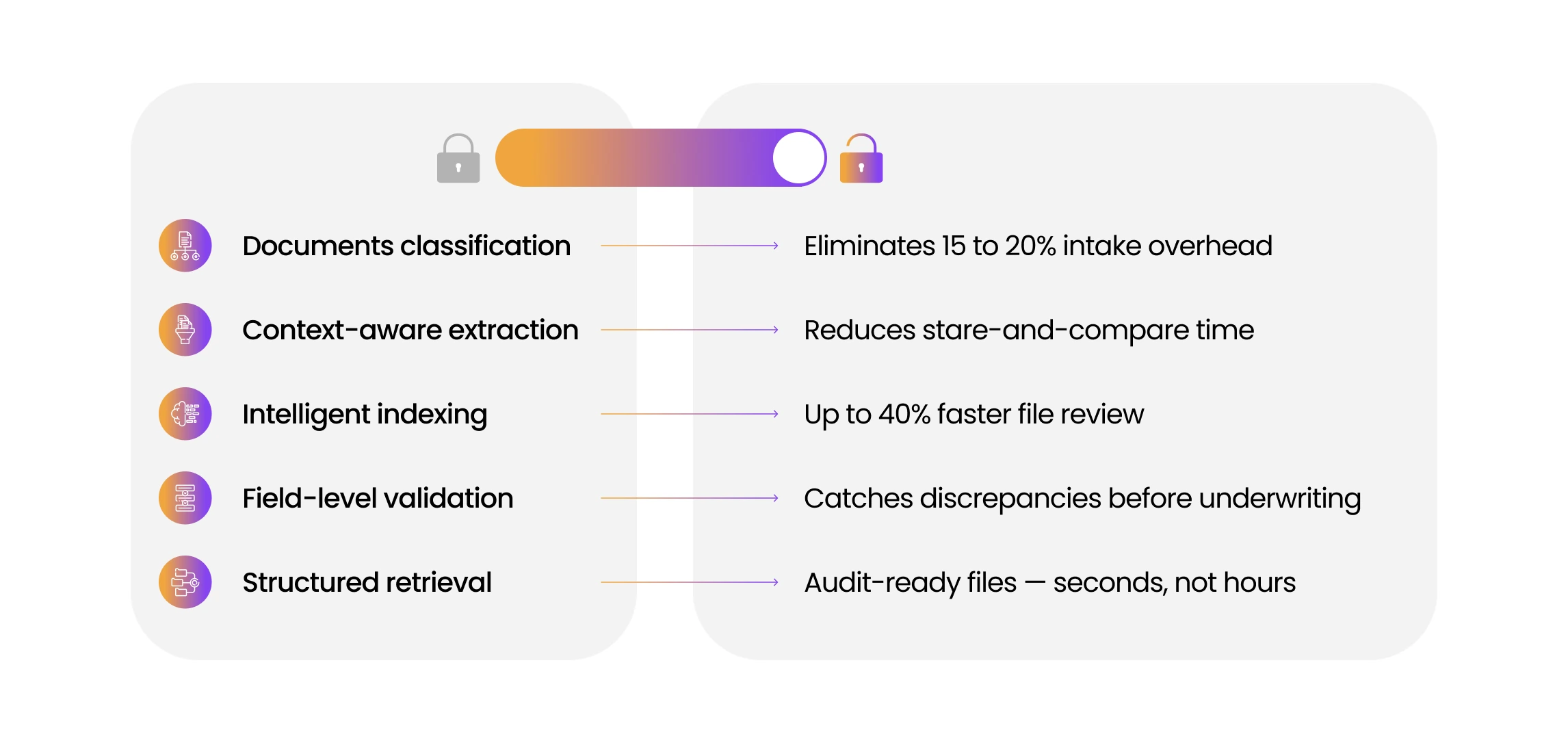
- Automated Document Classification
At intake, the system identifies and categorizes every document in the loan file — pay stubs, W-2s, 1003s, appraisals, lease agreements, bank statements — without manual sorting. Documents arriving via borrower portal, email, or fax are classified at ingestion and indexed into the correct position in the file structure. Classification errors that produce suspended files or misrouted documents are significantly reduced at the source. Processing teams no longer spend 15 to 20 percent of file time on intake organization. - Context-Aware Data Extraction
Legacy OCR reads characters. Context-aware extraction models are trained to recognize document structure. The system identifies field position within document type, recognizes variations in layout and terminology across sources, and extracts values with the surrounding context required to validate them. A gross monthly income figure extracted from a pay stub is retained with its pay period, employer, and YTD reference — not as an isolated number that can’t be verified against anything. Extraction accuracy at this level directly reduces stare-and-compare time for underwriters. - Intelligent Document Indexing
In a manual workflow, a 90-page loan file is often reviewed page by page. Indexed files allow underwriters to move directly to the document and field they need—with full context of where that document sits within the file, whether it satisfies a checklist requirement, and whether it has been validated. In many document-heavy workflows, intelligent indexing can materially reduce file review time, often by 25 to 40%, while helping ensure required documents are identified before a credit decision is rendered. A missing document is not just an oversight—it can create funding delays and potential compliance gaps. - Automated Field-Level Validation
Validation is where manual processes fail most expensively. An income figure that doesn’t reconcile across a pay stub, bank statement, and 1003 will either delay the loan when discovered in underwriting or create a defect when discovered post-close. Automated field-level validation applies rule sets at extraction — cross-referencing figures across document types, flagging discrepancies with specific attribution to the source document and field, and surfacing exceptions before the file advances. The underwriter receives a file with clearly identified and prioritized exceptions — not a file that requires discovery. - Structured Document Retrieval
Audit requests, investor queries, and quality control reviews all require rapid, accurate retrieval of specific documents and data points from closed loan files. When documents are indexed and field-level data is structured at the point of processing, retrieval takes seconds. When files are stored as unstructured document stacks, retrieval requires manual search across hundreds of pages — a process that introduces both delay and error risk. Structured retrieval is not an audit convenience. It is a critical capability for secondary market readiness and a QC infrastructure component that affects repurchase exposure.
These five capabilities don’t optimize a manual process. They replace the manual steps that were never efficient to begin with.
How DocVu.AI Removes the Document Constraint
DocVu.AI applies all five capabilities within a single IDP platform designed specifically for mortgage document workflows. The system ingests diverse loan document formats without template dependency; handling native PDFs, scanned files, photographed pages, and mixed-format packages through the same processing pipeline with consistent output.
Classification, extraction, indexing, validation, and retrieval operate as connected functions rather than isolated tools. A document classified at intake is indexed with its extracted data and immediately subject to cross-document validation rules. Exceptions are attributed, flagged, and visible to the processing team before any manual review is required.
For operations teams managing DSCR, Non-QM, or high-volume conventional pipelines, the practical result is measurable: processing time per file decreases, exception handling becomes proactive rather than reactive, and underwriters work from files that are complete, validated, and audit-ready at the point of review.
Throughput scales without requiring proportional headcount growth. A team processing 200 loans per month at capacity can often increase output significantly with the same staffing levels when document-processing constraints are reduced rather than managed around, with results depending on workflow maturity, loan complexity, and current operational efficiency.
Operational efficiency in mortgage lending is not a staffing question. It is a systems question. The constraint is in the document workflow, and that is exactly where it has to be solved.
Next Step
Explore how DocVu.AI’s IDP platform eliminates document-level bottlenecks across your loan processing, underwriting, and compliance workflows. Visit docvu.ai to see the full capability stack in the context of your operational environment.






